Sign Manifesto


10
85
500
Low-Resource Language Evaluations
Our goal is to highlight real-world use cases of common health, agriculture and education audio questions and determine how well and how quickly different AI model combinations respond to these questions (as determined by their semantic similarity to expert provided "golden" answers).
Every evaluation, prompt, model settings and AI workflows are public and immediately forkable for organizations to test AI any workflow with your own data and use case. Organizations are encouraged to create audio evaluations with their own data too.
10
85
500


Pakistani and Nigerian Health
In April 2026, we evaluated the latest and best-performing private (Gemini 3.1, OpenAI 5.4, Intron) and open source/sovereign deployable (Omnilingual, Gemma 4 26B, Kimi2.5) models for their performance on health-related audio questions in the languages commonly found in Pakistan and Nigeria. In our test, Gemini 3.1 Pro as the LLM + Intron or Meta's Omnilingual as the speech recognition model (ASR) scored most accurate, making the combination appropriate for WhatsApp and other async messaging based deployments, though likely too slow for usable voice-only services.
Pakistani Languages
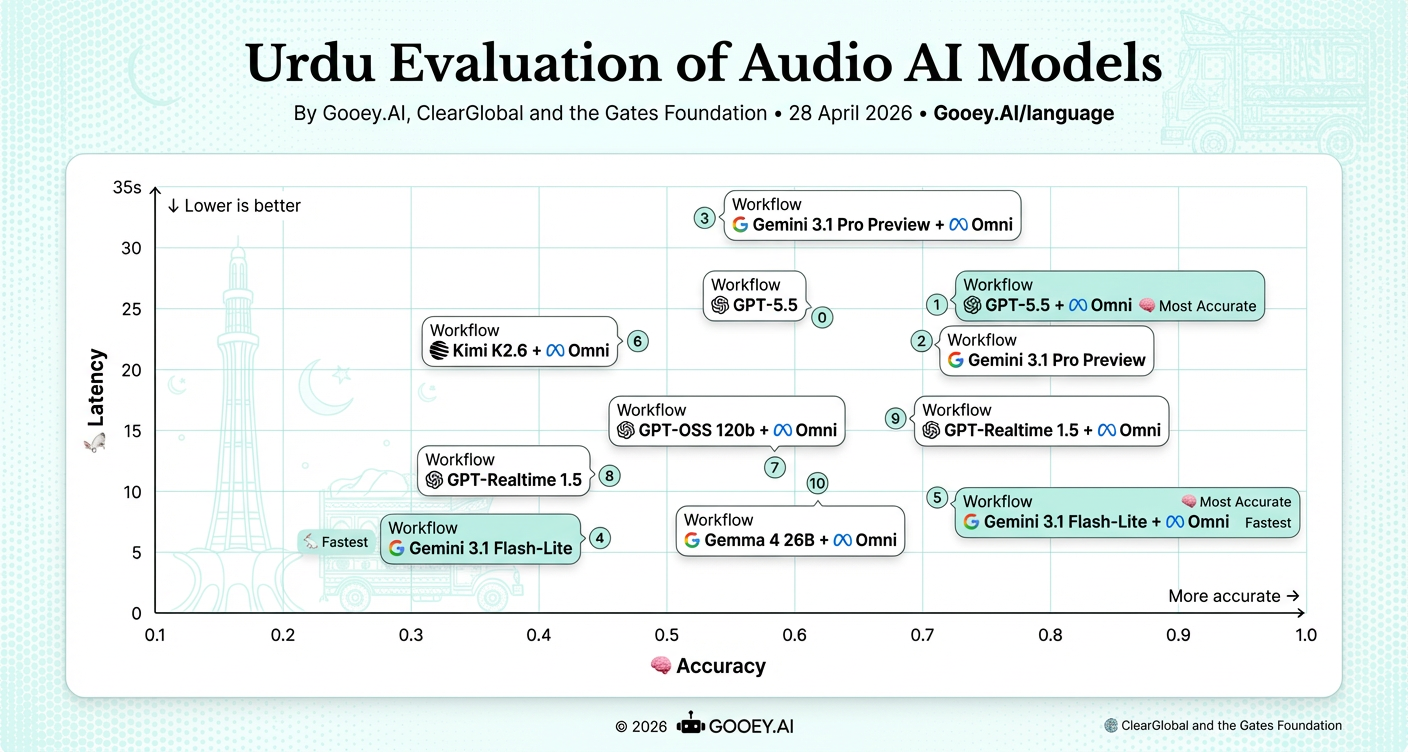
For Urdu, GPT-5.5 + Omni and Gemini 3.1 Flash-Lite + Omni both lead on accuracy at ~0.7, with Flash-Lite + Omni also the fastest among the top performers, and in general, at ~9s latency. Gemini 3.1 Pro Preview + Omni has fairly good accuracy but the highest latency (~32s), making it better suited to async use cases.
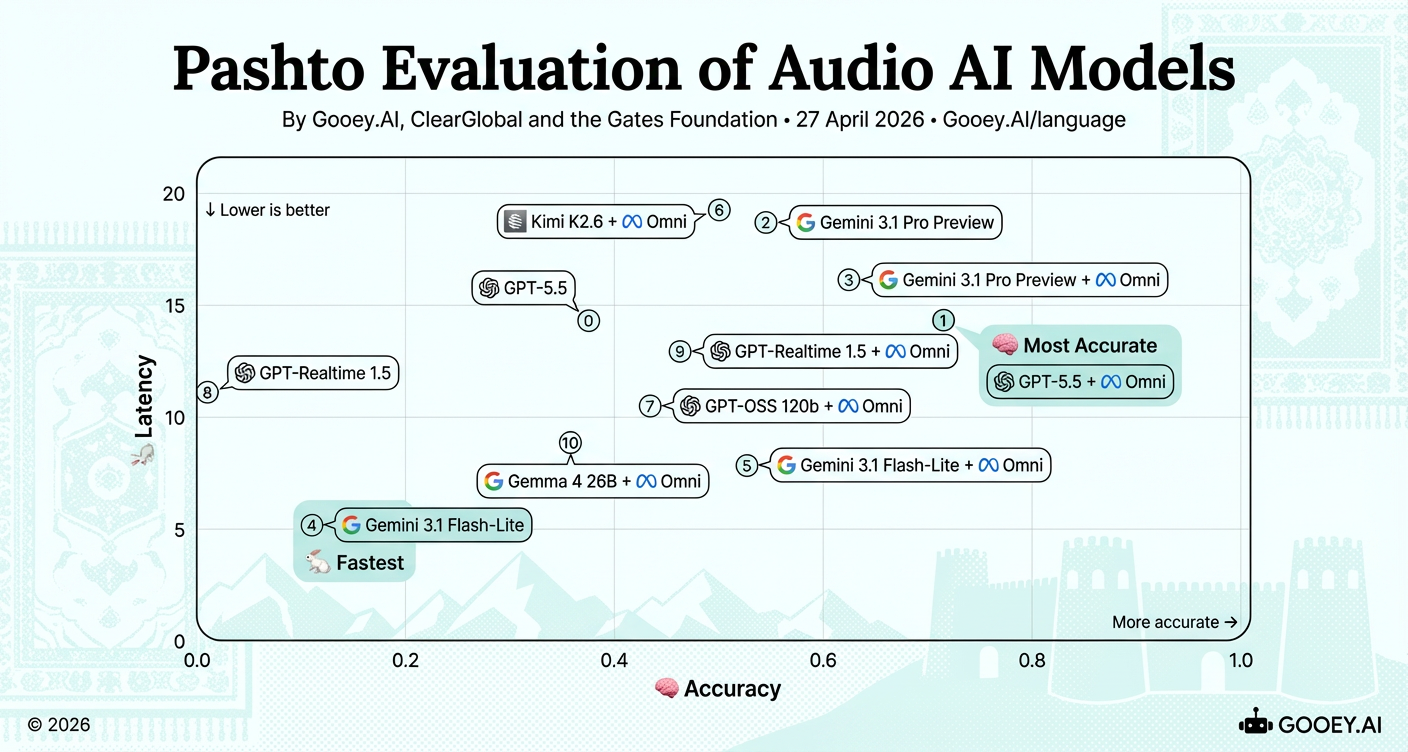
For Pashto, GPT-5.5 + Omni clearly leads on accuracy (~0.71) with moderate latency (~14s). Compared with the Urdu results, Pashto appears more accuracy-constrained overall: even the top model scores are lower than Urdu’s best performers, and the strongest real-time balance is likely Gemini 3.1 Flash-Lite + Omni, which keeps latency under ~8.5s while reaching mid-range accuracy.
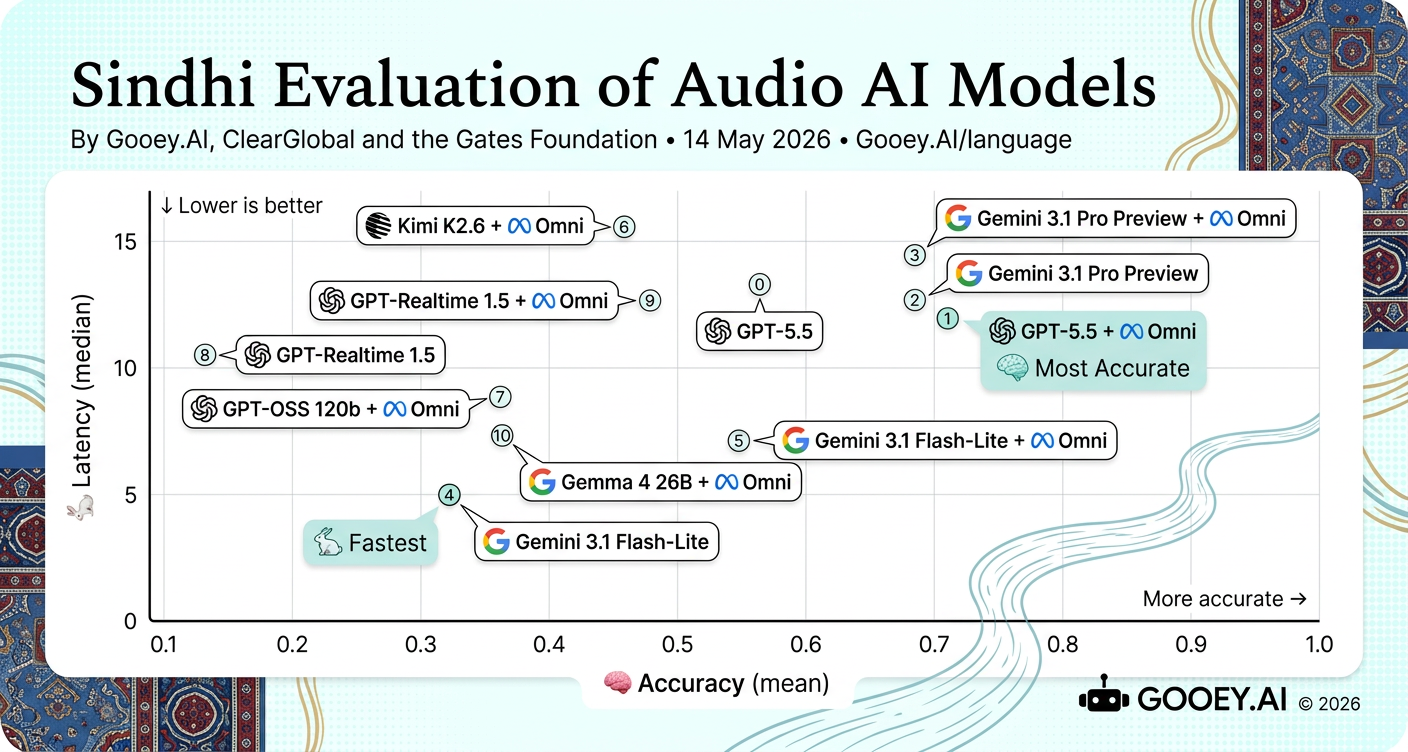
For Sindhi, GPT-5.5 + Omni is the most accurate option (~0.73) at roughly 12s latency, with Gemini 3.1 Pro Preview and Gemini 3.1 Pro Preview + Omni close behind but slightly slower. Compared with Urdu, Sindhi’s top accuracy is lower, but it looks closer to Pashto in overall performance; Gemini 3.1 Flash-Lite + Omni again offers the practical speed–accuracy middle ground.
Nigerian Languages
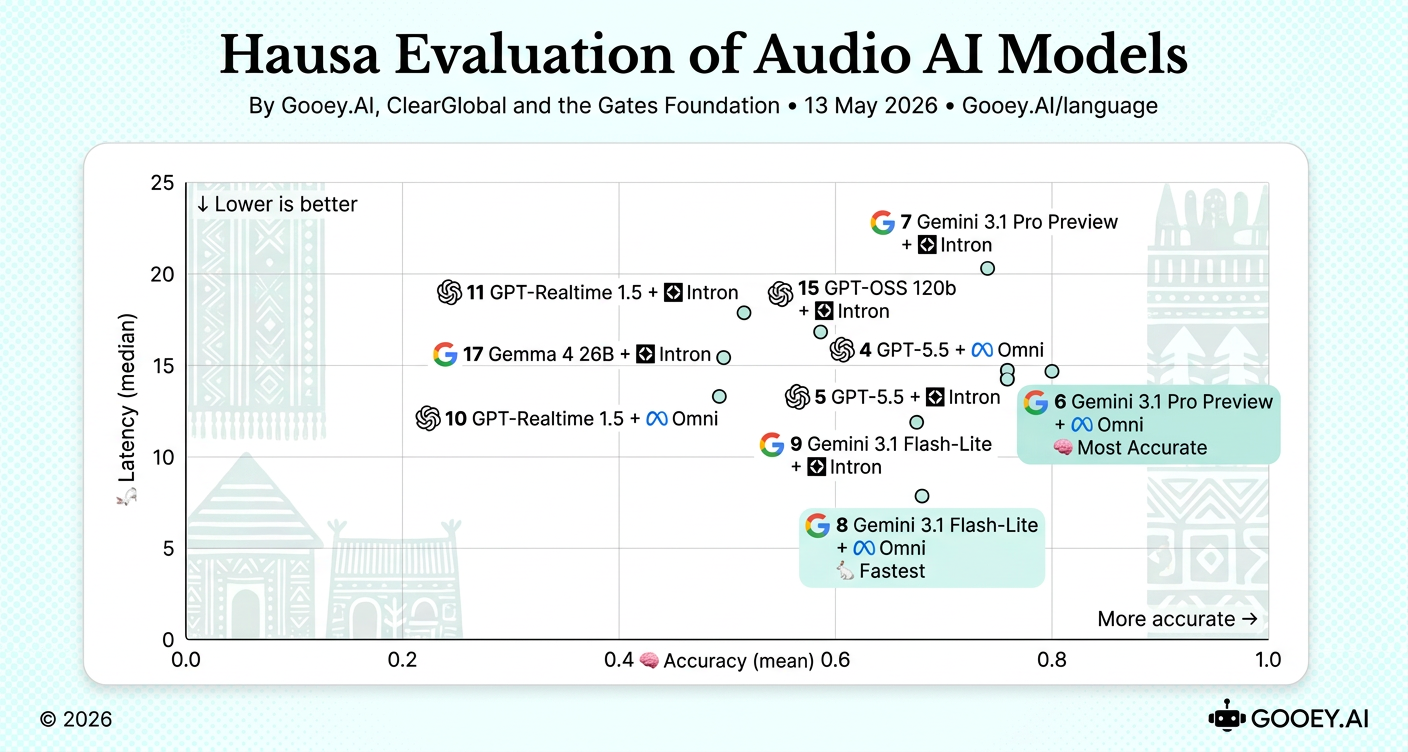
For Hausa, Gemini 3.1 Pro Preview + Omni is the most accurate combination (~0.79) with moderate latency around 14.73s. Gemini 3.1 Flash-Lite + Omni offers the best real-time balance, reaching strong accuracy (~0.66) at relatively low latency (~7.78s).Note: The following model combinations were not included due to subpar accuracy, high latency, or a combination of both - GPT-5.5, Gemini 3.1 Pro Preview, Gemini 3.1 Flash-Lite, GPT-Realtime 1.5, Kimi K2.6 + Omni, Kimi K2.6 + Intron, GPT-OSS 120b + Omni, Gemma 4 26B + Omni.
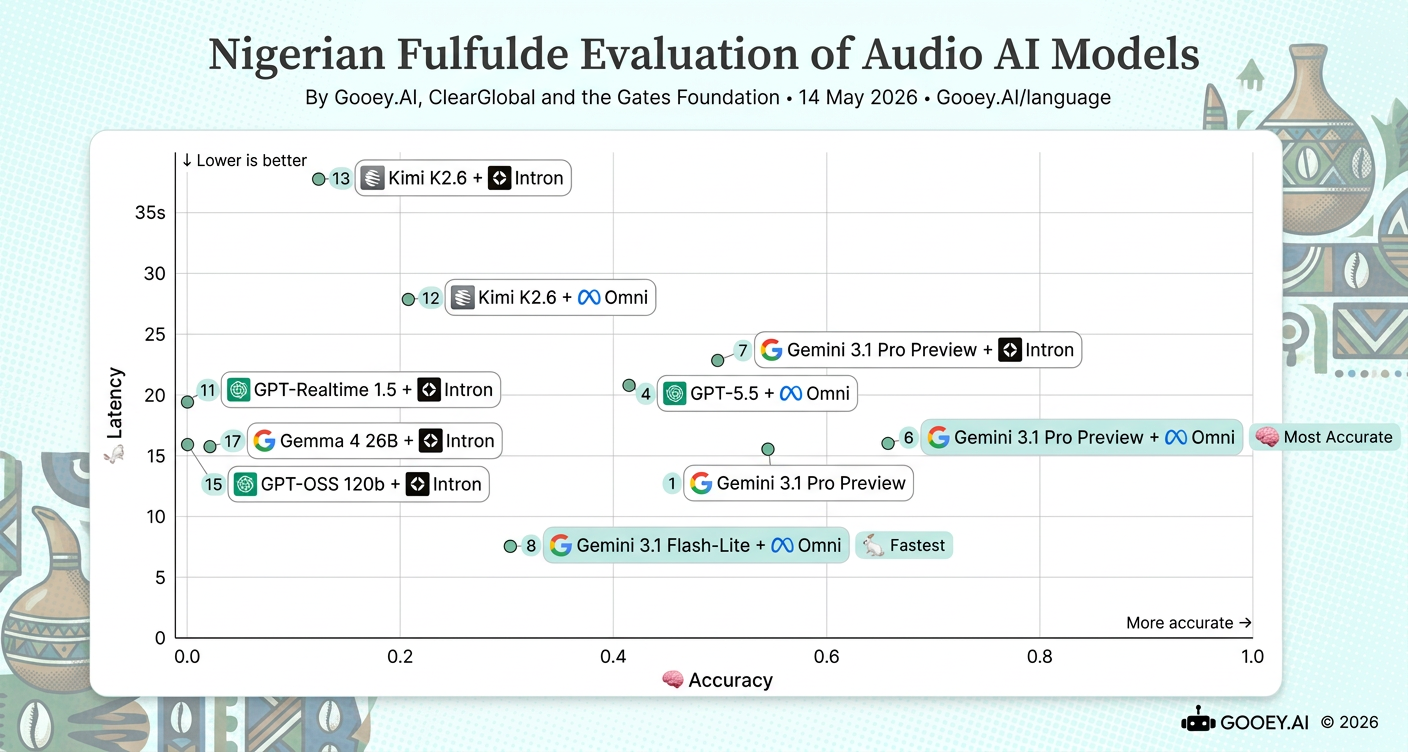
For Nigerian Fulfulde, Gemini 3.1 Pro Preview + Omni has the highest accuracy score at roughly ~0.68, with latency around ~16s. Gemini 3.1 Flash-Lite + Omni is the fastest option at ~7.5s and may be the most practical real-time choice, though it gives up a noticeable amount of accuracy compared with the top model at ~0.33.
Note: The following model combinations were not included due to low performance - GPT-5.5, Gemini 3.1 Flash-Lite, GPT-Realtime 1.5, GPT-5.5 + Intron, Gemini 3.1 Flash-Lite + Intron, GPT-Realtime 1.5 + Omni, GPT-OSS 120b + Omni, Gemma 4 26B + Omni.
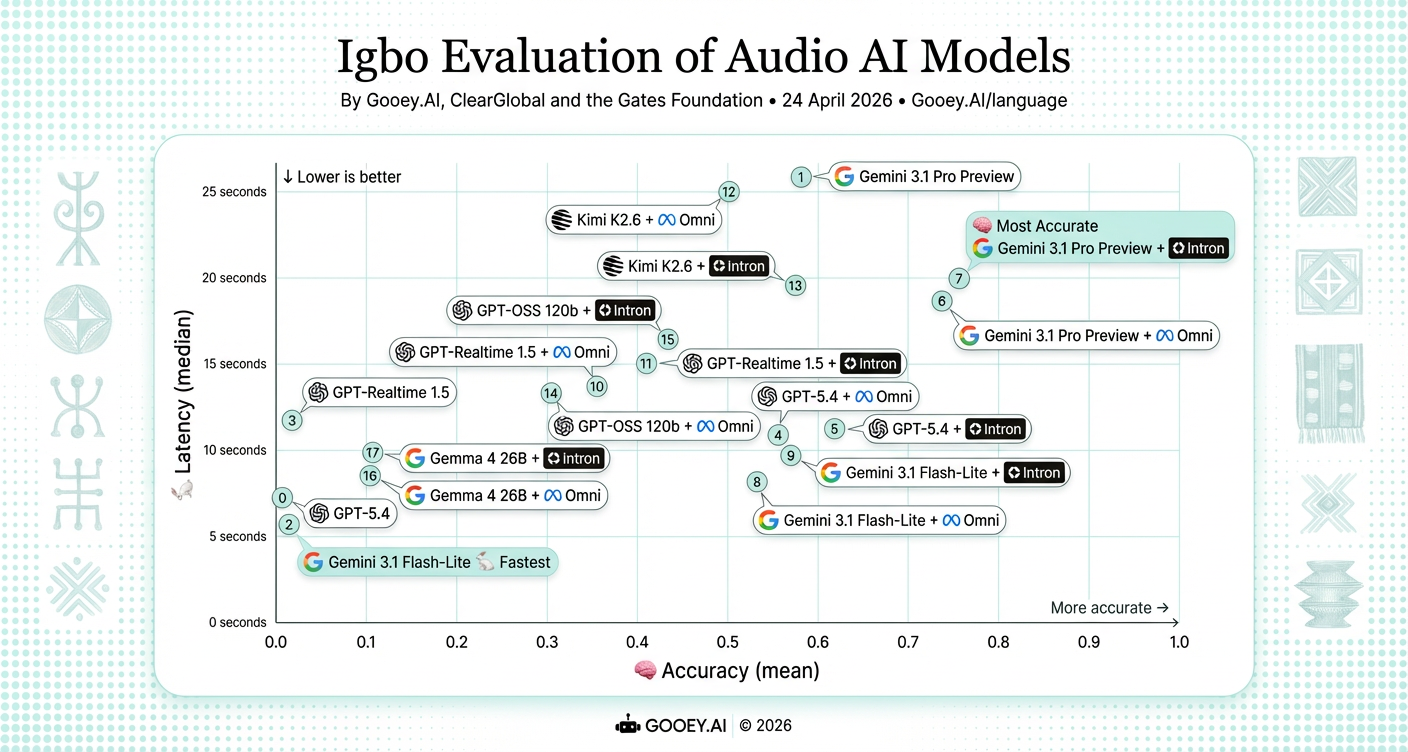
For Igbo, Gemini 3.1 Pro Preview + Intron ranks highest on accuracy (~0.74) but carries higher latency at around 20s, making it better suited to async workflows. Gemini 3.1 Flash-Lite + Omni offers the strongest speed–accuracy balance among lower-latency options.
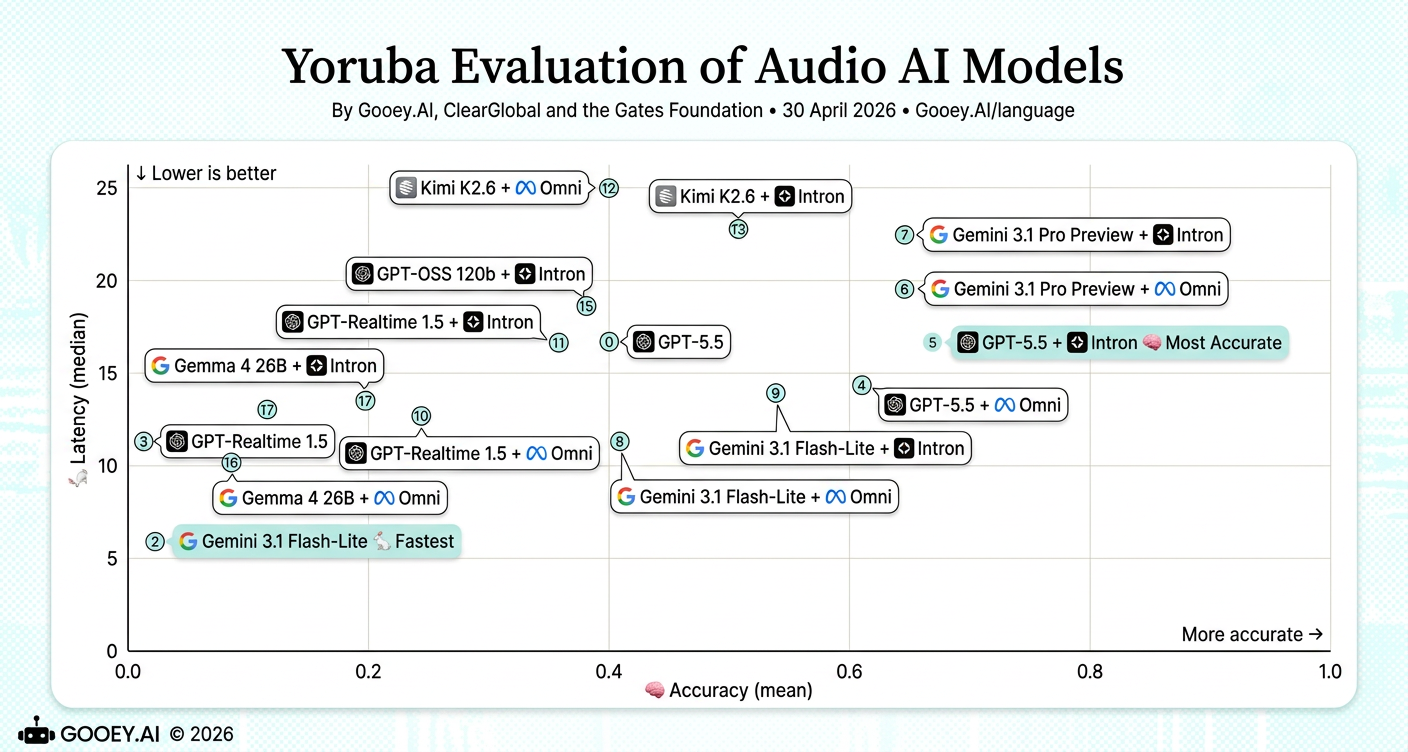
For Yoruba, GPT-5.5 + Intron is the most accurate model combination (~0.66) with moderate latency at around 16–17s, while Gemini 3.1 Pro Preview pairings also perform strongly but take longer. GPT-5.5 + Omni and Gemini 3.1 Flash-Lite + Intron offer stronger mid-latency speed–accuracy tradeoffs.
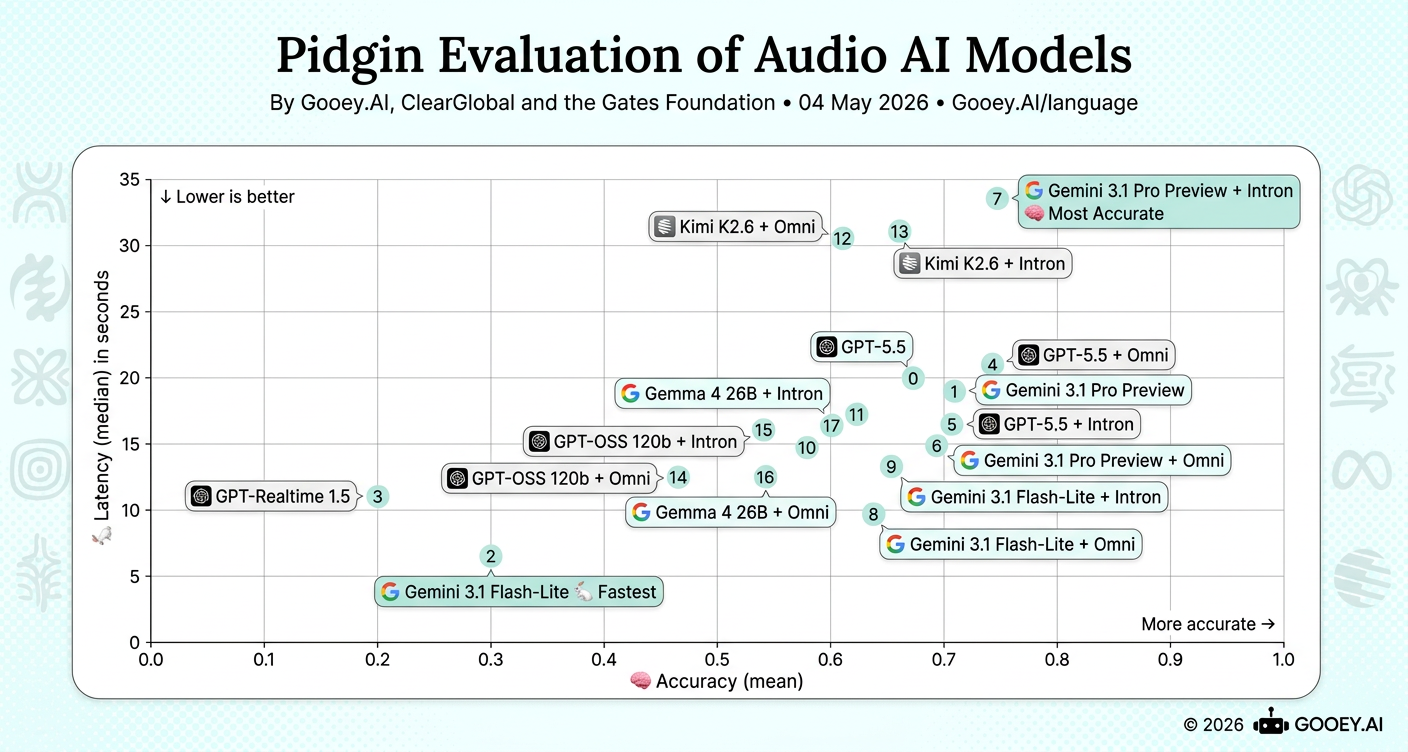
For Pidgin, Gemini 3.1 Pro Preview + Intron is the most accurate combination (~0.75) but has the highest latency at roughly 34s, making it better suited to async use cases while Gemini 3.1 Flash-Lite + Omni and Gemini 3.1 Flash-Lite + Intron offer stronger real-time tradeoffs around ~0.65 accuracy with ~9–13s latency.
Kinyarwanda, Swahili and Kikuyu
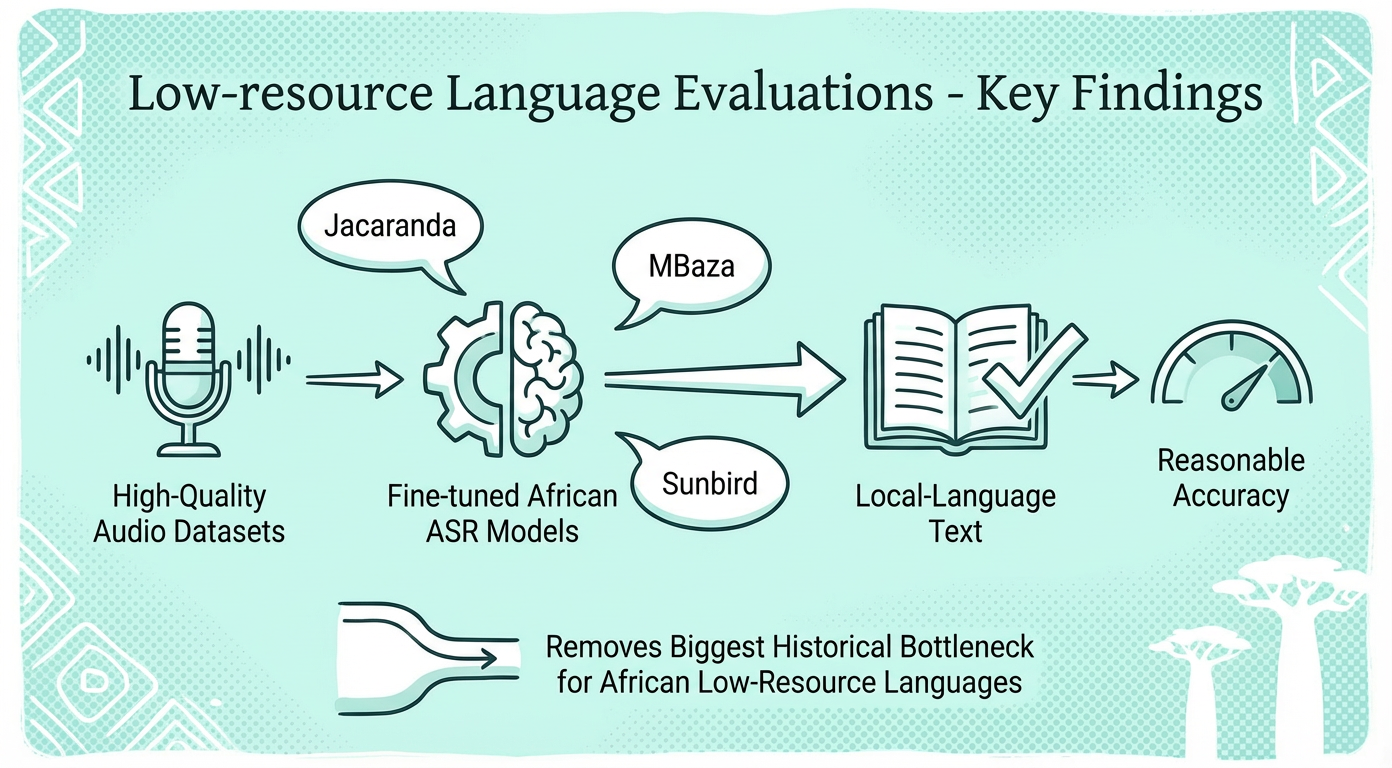
In December, 2025 We tested new LLM+ASR AI workflows to understand real-world deployment Swahili, Kikuyu, and Kinyarwanda voice applications. Fine-tuned African ASR models + modern LLMs (GPT-5.1, Gemini 3) achieved 85-96% accuracy with 4-10 second response times—fast enough for phone-based services. In short, Voice AI for many African languages is now technically viable for WhatsApp and basic phone deployments at scale.
Read the Paper
With Kinyarwanda, we found newer open-source models (KimiK2, GLM4.7, MiniMax2.1, DeepSeek3.2) offer a clear accuracy uplift over Qwen3. For phone-based voice apps, MBaza combined with GPTOSS provides the best speed/accuracy tradeoff (~0.88 accuracy at ~4s latency) and is likely most appropriate. For asynchronous use (WhatsApp voice), higher-accuracy but slower stacks such as MBaza+Gem3pro yield more accurate answers despite increased latency for constrained networks and basic phones today.

With Swahili, we found that the OpenAI realtime models tended to perform poorly on both accuracy and latency, with the fine-tuned Jacaranda Health model in combination with GPT 4.1 and 5.1 offering a reasonable combination of both speed and accuracy and hence, likely most appropriate for voice applications. For async applications like WhatsApp voice messages, Jacaranda plus Gemini 3 Pro gave the most accurate answers.
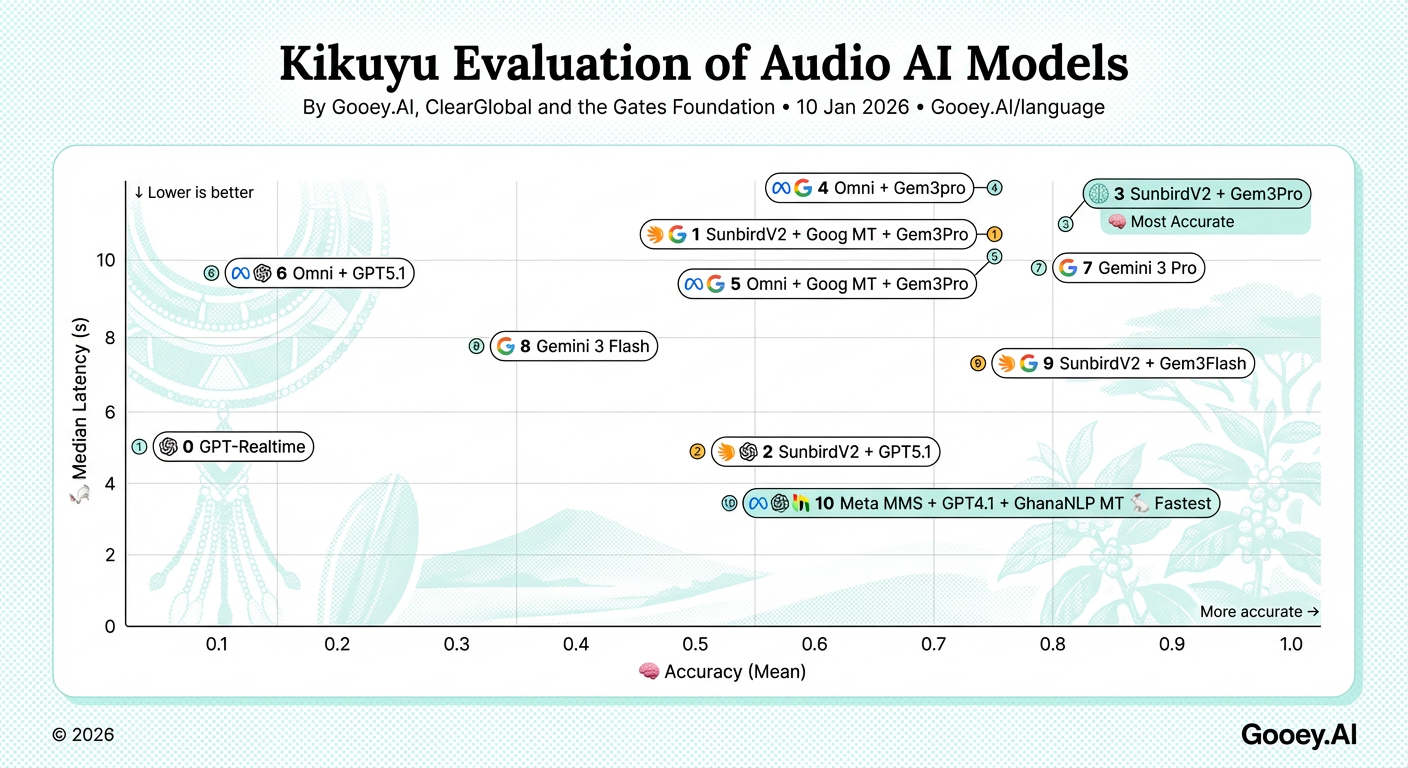
In general, the top performing models in Kikuyu collectively perform worse that Swahili and Kinyarwanda. Additionally, as of Dec 2025, our tested machine translation models between English and Kikuyu were limited to just GhanaNLP’s. Nonetheless, SunbirdV2 + Gemini 3 (both Pro and Flash) offer reasonable accuracy with median latency times of 7 and 10 seconds respectively. These offer latency times low enough for async voice messaging but are likely still too slow for usable voice based feature phone applications.
Theory of Change


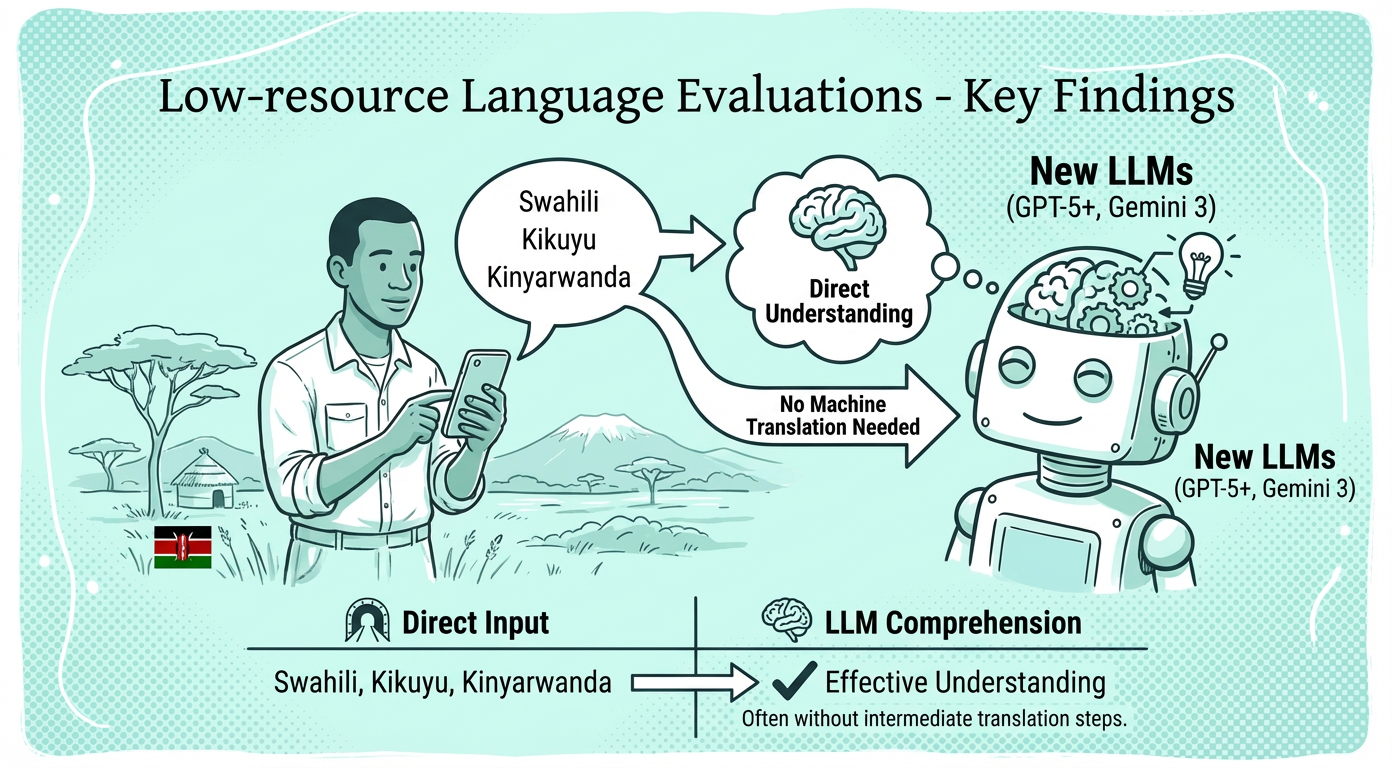
New LLM generations (GPT-5+, Gemini 3) dramatically improved multilingual text comprehension of local-language text.
.png)
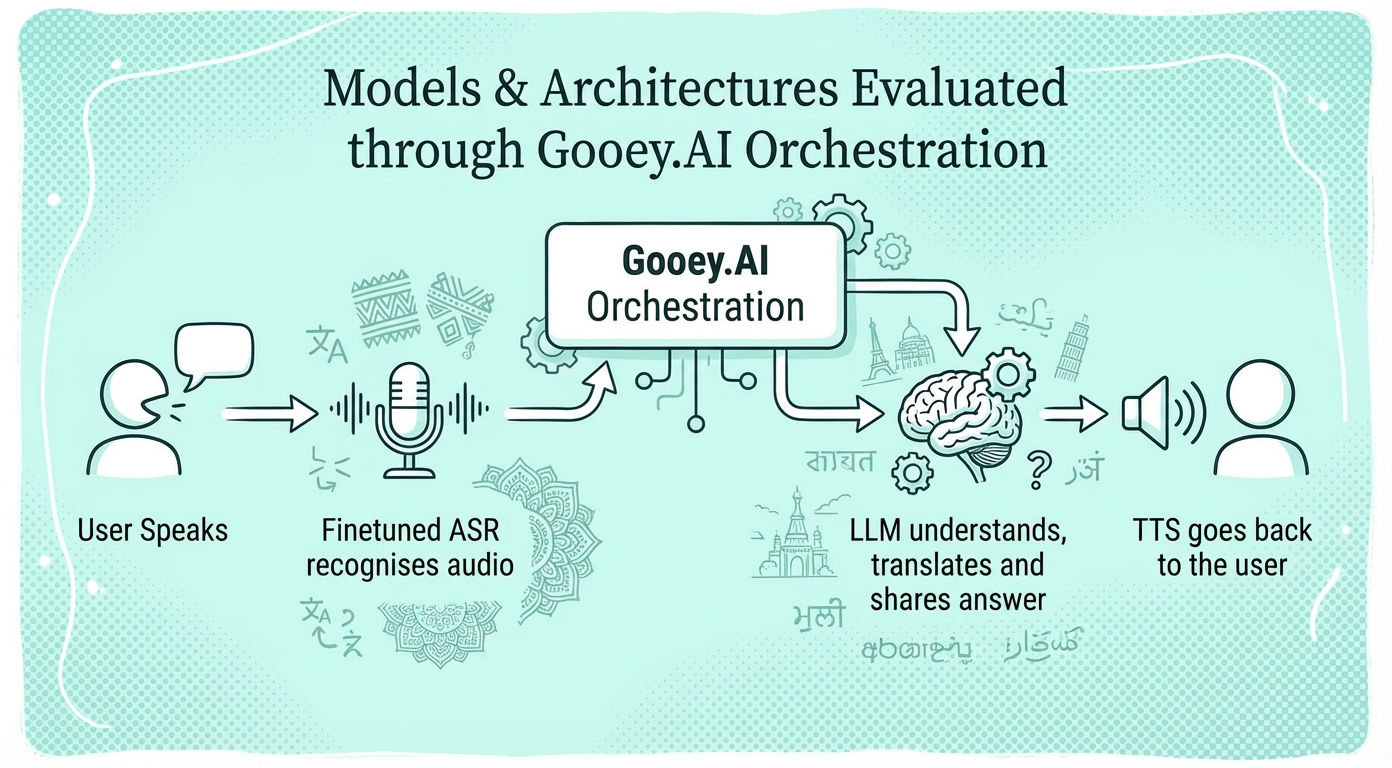
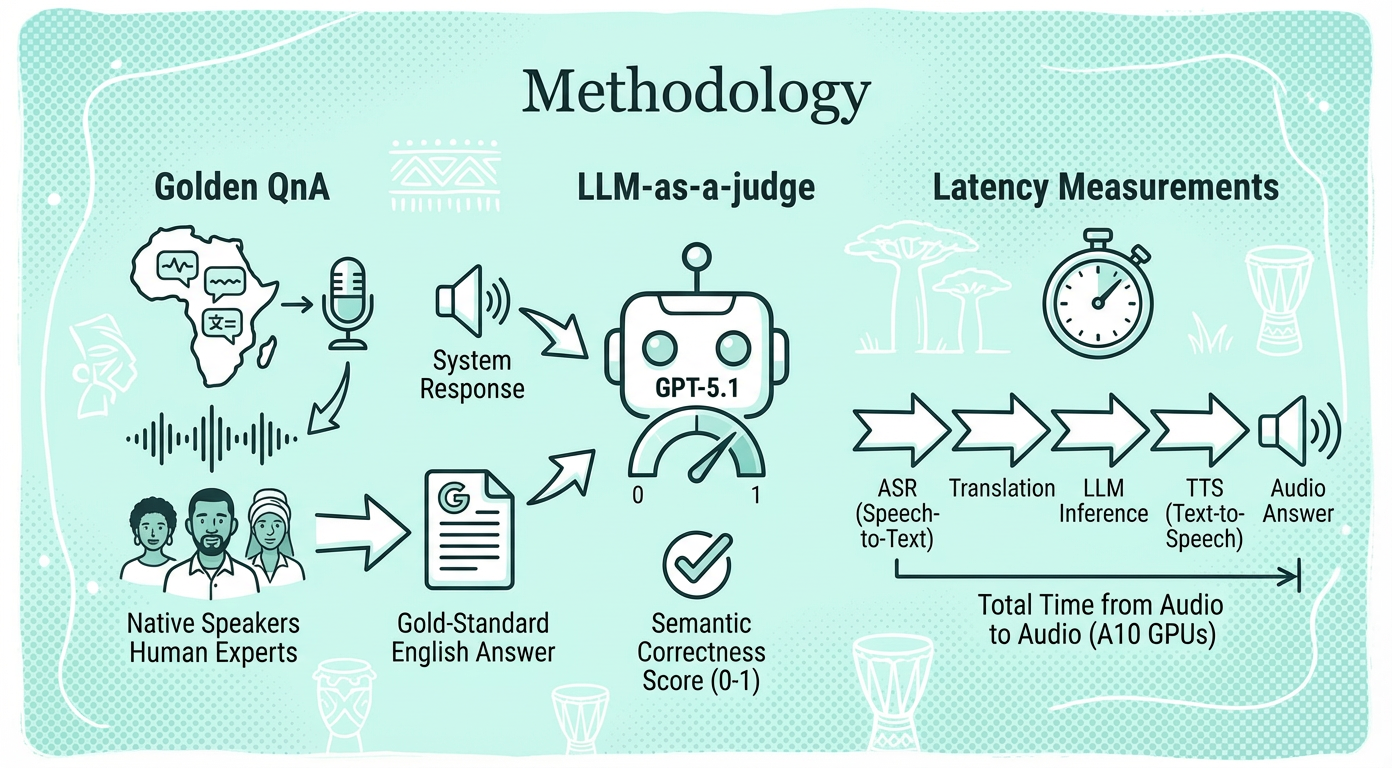
Native speakers record audio questions in three African languages; human experts provide gold-standard English answers for consistent evaluation across systems.
LLM-as-a-judge
GPT-5.1 scores system responses against expert answers on 0-1 scale, measuring semantic correctness since African language evaluation remains unreliable.
Latency measurements
Measures total time from audio question to audio answer, including ASR, translation, LLM inference, and TTS on A10 GPUs.

.png)
